Motivation
多模态NMT系统,在传统面向源语言词的 attention 机制基础上,增加整合了 spatial visual features 的 visual attention 机制,即 Doubly-Attentive
Methods
Conditional GRU
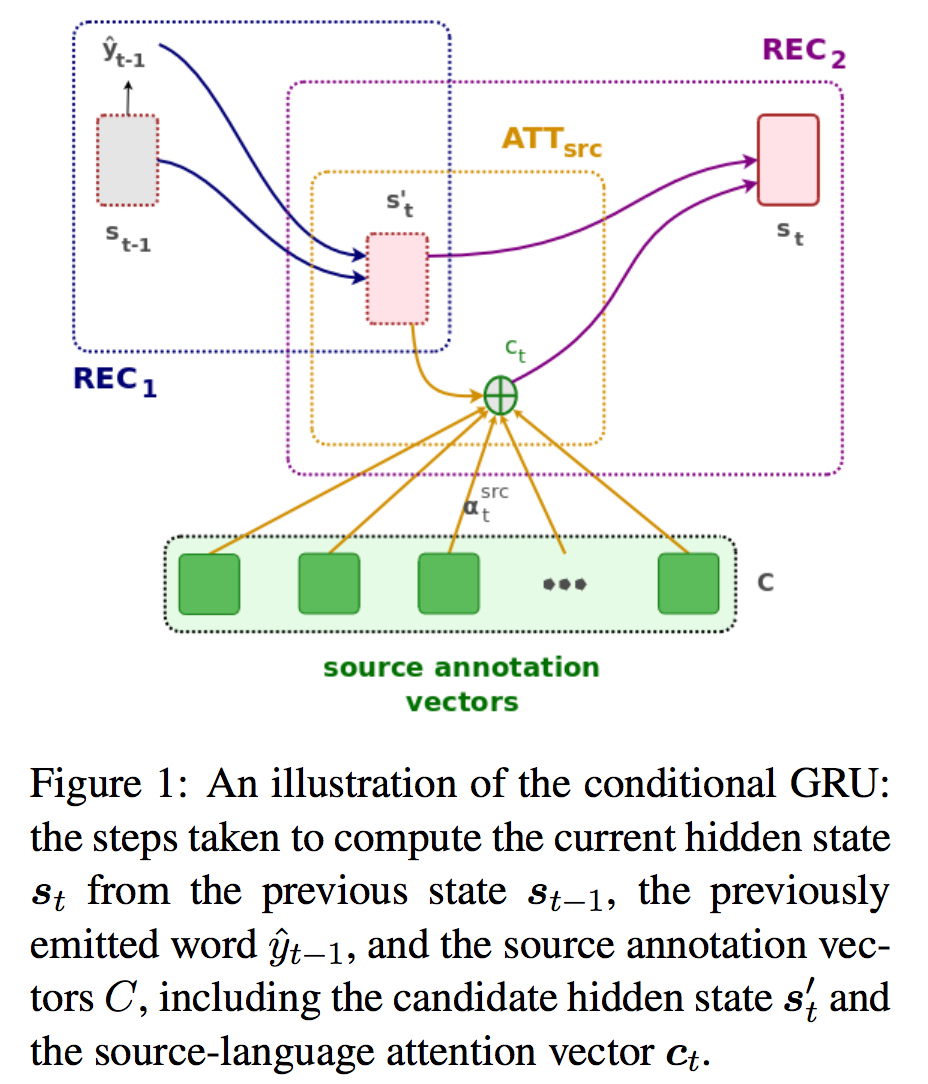
即 decoder 在计算 hidden states 时加入 context
NMT + IMG
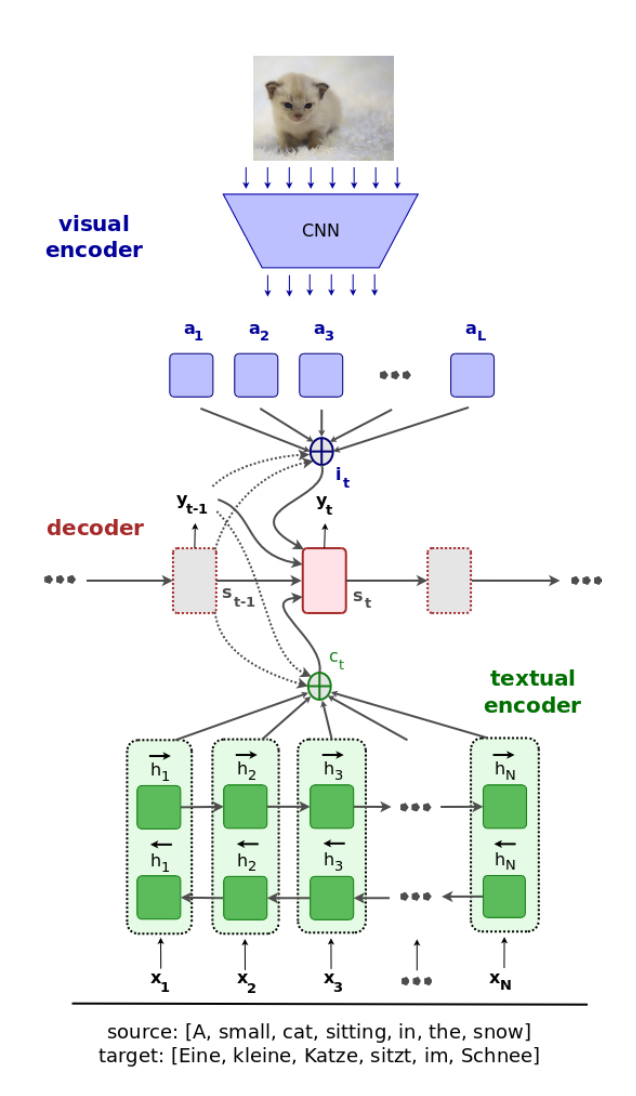
将图片分成 14 X 14 的网格,每个网格经预训练的 ResNet-50 表示为 1024 维的特征向量, 总共有 L = 196 个特征, 使用普通的基于 forward network 的 attention 函数计算 attention vector 即 $i_t$
与传统使用的 attention 机制不同的是,这里加入了一个 gating scalar 即 $\beta_t$
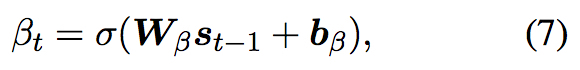
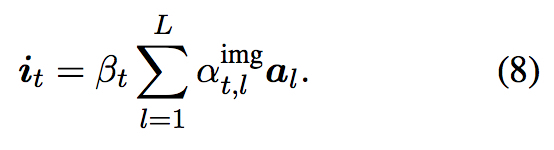
$i_{t}$ 与 $c_{t}$ 作为两个 attention 加入到隐状态的计算中,因此是 Doubly-Attentive
Experiments
采用一个由 Flickr30k 转化来的数据集 Multi30k,并分成了 M30kT 和 M30kC 两个不同的数据集
其中 M30kT 用来做模型训练和验证
同时还分别实验了在使用 M30kC (in-domain multi-modal) 和 WMT15 (general-domain text-only)预训练后的结果,以证明模型的优越性和鲁棒性
Questions
- 为什么只在 decoder 中将 图片信息作为 attention 加入进去?能在源端进行图片参考吗?